
 方言语音识别综述
方言语音识别综述
Mandarin speech recognition (MSR) --> dialect speech recognition (DSR)
# 中国方言概述
- 一般来说,中国方言可分为十类,即北方官话(普通话)、晋语、吴语、回族、平话、赣语、湘语、闽语、粤语和客家话。
- 口音是一种从方言中获得语调和音韵的发音风格,这也是汉语ASR识别的挑战之一;
- 需要为方言准备发音词典、声学模型和语言模型;
- 发音词典:实现音素和字形之间的映射,有时也称为发音词典,为方言文本的转写提供韵律和声调参考,为了方便查找和使用相关信息,已经开发了一些在线汉语方言发音词典;
- 语言模型:同传统ASR【N-gram】
- 声学模型:同传统ASR【GMM/ANN-HMM;CTC;Attention】
- 当数据相对较少时,使用传统建模方法:动态弯(DTW)【孤立词识别】、HMM之类的,需要标注时进行强制对齐;
- 实验证明DNN-HMM>GMM-HMM,2021年构建了基于CNN的声学模型用于维吾尔语识别,--LSTM--BiLSTM;
- 端到端的基本就两种机制:CTC【成都、藏语】和注意力机制【赣方言、大同方言】
- 一些挑战
- 数据集的建立;
- 方言的时变性;
- 多方言/方言+普通话;
- DSR具有微信版、网络版、综合媒体钱包、即时翻译软件、在线方言服务等形式。此外,还有基于方言语音服务的商用家用机器人,如Ava导医机器人和华龙医疗机器人。Spectrum开发和推广的智能医疗扬声器还能听懂方言和重口音普通话。
- 讯飞方言云服务:支持24种方言的识别和合成,为家电厂商提供全方位的方言识别技术。广东话、四川话、东北话、河南话、天津话、山东话、宁夏话的准确率均在90%以上。【微软、字节】
- 多语言ASR:wav2vec 2.0
- 模型优化
- 迁移学习:在特定方言上微调【2021年,拉萨语和藏语的跨语音识别模型】
- 生成对抗模型:生成特定地区的语音样本
- 多任务学习:低资源多方言场景
# 山西方言
方言特点
- 国内31省方言大概分为9个区域,山西方言属于“晋语”,中国北方唯一的“非官话”语言;
- 山西方言还在使用的最多的是名词和动词,其次是形容词,名词:“胰子”(香皂)、“记性”(记忆力)等;动词:“圪蹴”(蹲下)、“抠搜”(吝啬)、“锄倒”(摔倒)等;形容词:“摆到”(不知道)等。
《语音识别系统在山西方言中的实现与应用》2021年
- 模型:GMM-HMM/DNN-HMM,实现:Kaldi/HTK;
- 1000条方言词句用于训练;
- 在对朔州不同口音进行地区录取,结合所划区域,录音人大体分布在朔城区、怀仁县、右玉县、山阴县、应县这五个区域。由于普通话受到城镇化的影响,一些重要的方言特殊词难以听到,所以录音人大多选择口音浓重村乡的成年人或者青年人;
- 查阅《朔州方言志》,得到20个声母,38个韵母,采用国际音标(IPA)+声调标注
《山西朔州方言语音识别方法研究》2020年
- GMM-HMM声学模型在小区域和低资源数据量的情况下,识别率较高,随着数据量的加大,基 声学模型的准确率逐渐提升,基于DNN-HMM声学模型的准确率逐渐超越;
《山西省公安厅对语言识别技术进行鉴定》:编印出《山西省方言常用词语集》和《山西方言词汇》
《山西大同地方方言语音识别技术及应用研究》2020年
- 大同方言相比于普通话多出了“入声”声调,入声发音短促,一发即收,音频的持续时间更短,提出多核卷积融合网络来提取语谱图中不同持续时长的音素特征,放在声学模型之前;
- 构建数据集:总时长9小时29分16秒,共11678条;
- 中北大学软件学院本科面向全山西招生,所以,院里学生都是山西本地人,全院3000多名本科在读学生。同学们通过采访、聊天、朗诵等形式收集到不同的语音语料,语音包括自然语音与朗读语音,内容涉及山西各地的风土人情、文化旅游等多个方面。
# 其他方言
- 《用于襄阳方言语音识别的人机交互系统研究》2023年
- 9440条,22个说话人,现场录制时分为慢读、正常读和快读;
- DNN-HMM优于GMM-HMM的各种优化策略;
- 以拼音作为建模单元搭建了CNN-CTC模型;
- 《基于深度学习的端到端南昌方言语音识别》2023年
- 6名南昌本地志愿者,对照特定文本,进行南昌方言录制,18.2小时,合计13988条;
- 使用Conformer-Transducer对普通话训练,然后迁移学习;
- 对比实验表明,编码网络模块全部微调效果最好;
# 方言数据集
数据集 - MagicHub (opens new window),只有闽南、郑州、天津、济南、上海、武汉、西安、湖南、粤语、南昌、长沙
THUYG-20语料库:作为一个公开的维吾尔语语音数据集,THUYG20语料库由Aes Karrouz等人联合发表在《清华大学学报》上。该语料库记录在新疆30个地州,总音频时长为21h,涵盖了词汇中的45000多个单词,包括词素、音节和字符。共计348个语句。录音机利用IBM联想台式机的声卡和外部麦克风,在安静的环境中录制和阅读文学作品、新闻报道和其他材料。音频采样率为16 kHz,以单声道模式录制。由于THUYG-20语料库主要基于阅读材料,孤立词识别的表现令人印象深刻,但连续对话识别效果并不理想。
GCDC语料库:GCDC语料库中的方言属于赣方言。语料库总时长131.5小时,其中赣语发音69小时,普通话62.5小时。录音的文本内容包括新闻报道、小说、公告、诗歌、信件和散文六种类型,共310篇文献。语料库包括赣方言的19个子区,但他们的论文没有提及具体的录音信息,如音频采样率。
大同方言语料库:大同方言语料库由刘等发表在《中国北方大学学报(自然版)》上。该语料库收录了山西大同方言,总音频时长为12小时、21分钟和13秒,包括阅读和日常口语文本。共有8894条音频数据。大同方言语料库中的记录文本是相对均衡的。它能反映大同方言的声学特征。它适用于小方言的语音识别训练和测试,但说话人的数量和性别没有量化和分析。
RASC863语料库:RASC863(国家863计划资助的区域重音语音语料库)语料库是由中国社会科学院语言学研究所设计和构建的。第一批数据由上海、广州、厦门和重庆的4个地区口音组成,分别代表吴方言、越方言、闽方言和西南官话。它于2004年完成并出版。参与录制的志愿者人数为800人,使用USB声卡和电脑麦克风。每个地区有200人,男女比例均衡。阅读文本包括两种材料:阅读和自然说出的句子。第二批RASC863语料库包括6个其他地区口音:长沙、洛阳、南昌、太原、南昌和温州。RASC863包含丰富的方言口音内容,可以有效支持大规模语音识别系统的建设和应用。
混合口音普通话语料库:混合口音普通话语料是DataHall录制的一个开源语料库。录制音频全长200小时,共有6300名志愿者参与录制,男女比例1:1,覆盖广东、福建等34个省份。演讲者随机选择带有口音的普通话对话话题,并在安静的环境中使用安卓麦克风进行录音。音频采样率为16 kHz。该语料库中的语音数据包含多个位置,覆盖了广泛的口音,适用于大规模的口音语音识别系统。
语料库一般由阅读材料和日常口语两部分组成,当地的影视素材、新闻、广播音频可以是很好的数据集,应包括不同性别、年龄、社会背景和教育背景的说话人;
Praat软件被广泛用于标注方言字典中文本的声调和拼音;
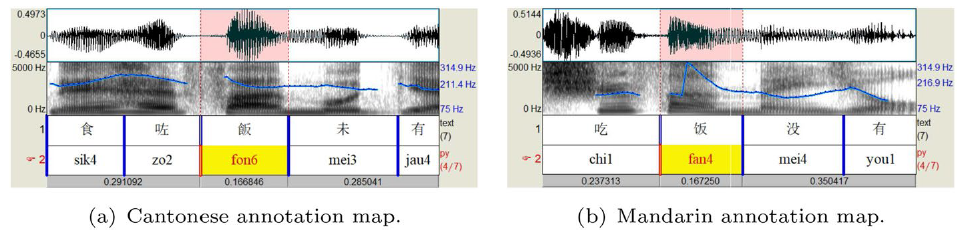
# 其他
方言的调值与普通话不同,普通话分为12345,方言需要用Praat软件分析出调值【五度标记法】;
# 参考资料
- 声调T值法实验报告_praat怎么分析声调-CSDN博客 (opens new window)
- 五度标记法_百度百科 (baidu.com) (opens new window)
- 兴安方言声调调值测试 - 知乎 (zhihu.com) (opens new window)
- 《Chinese dialect speech recognition: a comprehensive survey》